Throughout this series, we have explored the various perspectives of AWS CAF, providing valuable insights and practical guidance to help organizations successfully embrace the power of the cloud. The Operations Perspective within AWS CAF focuses on optimizing the health, availability, and performance of cloud services, aligned with the specific needs and goals of your organization. This perspective encompasses a range of capabilities outlined below, and involves various stakeholders such as infrastructure and operations leaders, site reliability engineers, and information technology service managers. 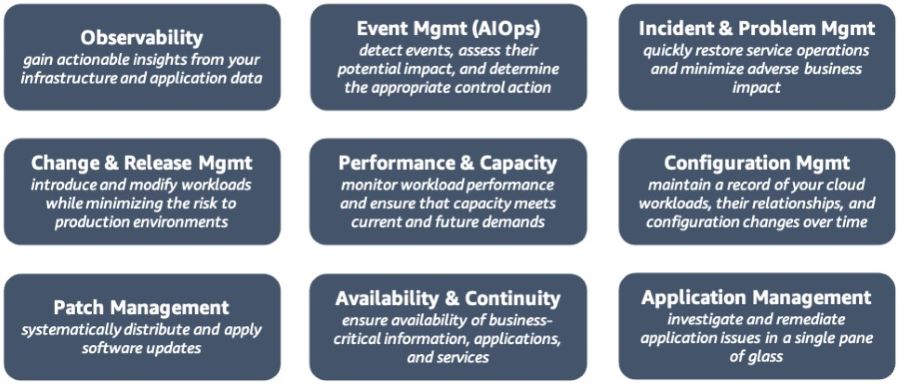 Figure 1: AWS CAF Operations perspective capabilities Observability Observability is a critical capability that enables organizations to derive valuable insights from their infrastructure and application data. Operating at cloud speed and scale requires the ability to proactively identify issues before they disrupt the customer experience. To achieve this, it is essential to develop comprehensive telemetry comprising logs, metrics, and traces that provide a deep understanding of the internal state and health of workloads. Monitoring application endpoints and assessing their impact on end users is crucial for maintaining optimal performance. By generating alerts when measurements exceed predefined thresholds, organizations can quickly address potential problems. Synthetic monitoring, which involves using configurable scripts scheduled to run at regular intervals, allows the creation of canaries to monitor endpoints and APIs effectively. Implementing traces provides visibility into the journey of requests throughout the entire application, enabling the identification of bottlenecks and performance issues. By leveraging metrics and logs, insights can be gained into the utilization of resources, servers, databases, and networks. Real-time analysis of time series data helps in understanding the causes behind performance impacts, facilitating prompt remediation. To consolidate observability data, organizations can centralize it in a single dashboard, providing a unified view of critical information about workloads and their performance. This centralized view enhances situational awareness and empowers teams to make informed decisions and take timely actions to optimize operations and ensure a seamless customer experience in the cloud environment. Event Management (AIOps) Event management, with the integration of Artificial Intelligence for IT Operations (AIOps), plays a crucial role in effectively detecting events, assessing their potential impact, and determining appropriate control actions. In order to optimize incident detection and response times, it is important to filter out irrelevant noise and focus on priority events that require immediate attention. Predicting impending resource exhaustion and automatically generating alerts and incidents enable proactive monitoring and mitigation of potential issues before they escalate. Furthermore, identifying likely causes and remediation actions helps in swiftly resolving incidents and minimizing their impact on operations. Establishing an event store pattern and harnessing the power of machine learning through AIOps allow for automated event correlation, anomaly detection, and causality determination. This enables organizations to efficiently analyze large volumes of event data and identify patterns or anomalies that might indicate underlying issues. Integration with cloud services and third-party tools, including incident management systems and processes, enhances the overall event management capabilities. By automating responses to events, organizations can reduce errors that may result from manual processes and ensure consistent and prompt actions, thereby improving incident response efficiency and effectiveness. Incident and Problem Management Incident and problem management aims to swiftly restore service operations and minimize adverse impacts on business operations. The adoption of cloud technology enables organizations to automate response processes for service issues and application health concerns, resulting in improved service uptime. As organizations transition to a more distributed operating model, it becomes essential to streamline interactions between relevant teams, tools, and processes. This streamlining facilitates the prompt resolution of critical and complex incidents, ensuring minimal disruption to operations. Within runbooks, it is important to define escalation paths that outline triggers and procedures for escalating incidents to appropriate personnel. Conducting incident response gamedays and incorporating lessons learned into runbooks allows organizations to enhance their incident management capabilities. By identifying incident patterns, organizations can determine underlying problems and implement corrective measures effectively. Leveraging chatbots and collaboration tools facilitates seamless communication and coordination among operations teams, tools, and workflows. Furthermore, adopting blameless post-incident analyses enables organizations to identify contributing factors to incidents without assigning blame. This approach encourages a focus on learning and improvement, leading to the development of targeted action plans to prevent similar incidents in the future. Change and Release Management Change and release management involves the introduction and modification of workloads while mitigating risks to production environments. Traditional release management is known for its complexity, slow deployment speed, and challenges associated with rollbacks. However, with the adoption of cloud technology, organizations can leverage Continuous Integration and Continuous Deployment (CI/CD) techniques to facilitate rapid release management and rollbacks. To align with the agility of the cloud, it is crucial to establish change processes that incorporate automated approval workflows. This enables seamless and efficient handling of changes. Deployment management systems should be utilized to effectively track and implement these changes. By adopting a strategy of frequent, small, and reversible changes, the scope of each modification is minimized, reducing potential disruptions. Thoroughly testing and validating changes at every stage of the lifecycle is essential to minimize the risks and impacts of failed deployments. Automating the rollback process to a previously known stable state is crucial in cases where desired outcomes are not achieved. This automated rollback mechanism reduces recovery time and minimizes errors that can occur with manual processes. Overall, embracing cloud technology and implementing effective change and release management practices enable organizations to introduce and modify workloads with reduced risk to production environments, while benefiting from the agility and efficiency of CI/CD techniques. Performance and Capacity Management Performance and capacity management involves monitoring the performance of workloads and ensuring that the available capacity meets both current and future demands. While the cloud offers virtually unlimited capacity, various factors such as service quotas, capacity reservations, and resource constraints can limit the actual capacity of your workloads. It is crucial to understand and effectively manage these capacity constraints. To achieve this, it is important to identify key stakeholders and reach a consensus on the objectives, scope, goals, and metrics of performance and capacity management. Collecting and processing performance data on a regular basis is necessary to track progress and report on performance against established targets. Periodically evaluating new technologies can help identify opportunities for performance improvements and recommend necessary changes to goals and metrics accordingly. Monitoring the utilization of workloads is essential for creating baselines that serve as reference points for future comparisons. By establishing thresholds, you can identify when it's necessary to expand capacity to meet increasing demands. Analyzing demand patterns over time is crucial to ensure that the capacity aligns with seasonal trends and fluctuating operating conditions. In summary, effective performance and capacity management require continuous monitoring of workload performance, understanding and addressing capacity constraints, engaging stakeholders, collecting performance data, and making informed decisions based on analysis to optimize performance and ensure sufficient capacity to meet evolving demands. Configuration Management When it comes to configuration management, it's essential to maintain accurate and complete records of all your cloud workloads, their relationships, and any changes made to their configurations over time. If not properly managed, the dynamic and virtual nature of cloud resource provisioning can lead to what's known as configuration drift, where things get out of sync. To stay on top of it, it's important to establish a tagging system that overlays your business attributes onto your cloud usage, allowing you to organize your resources based on technical, business, and security factors. Make sure to specify mandatory tags and enforce compliance through policies to ensure consistency. Leveraging infrastructure as code (IaC) and configuration management tools will simplify resource provisioning and lifecycle management. Lastly, establish configuration baselines and keep them up to date through version control, so you always have a solid reference point to work from. Patch Management When it comes to patch management, it's important to have a systematic approach in place to ensure the timely distribution and application of software updates. These updates address security vulnerabilities, fix bugs, and introduce new features to keep your systems running smoothly. By following a structured patch management process, you can take advantage of the latest updates while minimizing any risks to your production environments. To implement effective patch management, it's crucial to apply important updates during designated maintenance windows and prioritize critical security updates for immediate action. Providing advance notice to users about upcoming updates and giving them the option to defer patches when alternative mitigations are available can help maintain a smooth transition. Before rolling out patches to your production environment, it's advisable to update your machine images and thoroughly test the patches to ensure compatibility and stability. Considering separate maintenance windows for each Availability Zone (AZ) and environment will help ensure uninterrupted availability during the patching process. Regularly reviewing patching compliance and promptly notifying non-compliant teams to apply the required updates will help keep your systems secure and up to date. By staying vigilant in your patch management efforts, you can effectively protect your systems while keeping them running smoothly. Availability and Continuity Management In terms of ensuring the availability of business-critical information, applications, and services, availability and continuity management plays a vital role. To build robust cloud-enabled backup solutions, it's important to carefully assess your existing technology investments, recovery objectives, and available resources. By ensuring timely restoration after disasters and security events, you can maintain system availability and business continuity. One crucial aspect is to establish a well-defined schedule for backing up your data and documentation. This ensures that you have the necessary safeguards in place to protect your valuable assets. To enhance your overall preparedness, it's recommended to develop a disaster recovery plan as part of your broader business continuity strategy. This involves identifying potential threats, assessing risks, evaluating the impact, and estimating the costs associated with different disaster scenarios for each workload. By specifying Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs) accordingly, you can align your recovery efforts with business needs. Implementing a disaster recovery strategy that leverages multi-AZ or multi-Region architecture can provide added resilience and minimize potential disruptions. Additionally, considering the use of chaos engineering, which involves conducting controlled experiments to improve resiliency and performance, can further enhance your overall system robustness. It's crucial to regularly review and test your plans, ensuring they remain up to date and effective. By incorporating lessons learned from previous experiences, you can refine your approach and make any necessary adjustments to strengthen your availability and continuity management practices. Application Management When it comes to application management, the ability to investigate and resolve application issues from a single interface is crucial. By consolidating application data into a unified management console, you can simplify operational oversight and expedite the remediation process. This eliminates the need to constantly switch between various management tools, streamlining the workflow. To enhance efficiency further, it's important to integrate your application management with other operational and management systems. This includes systems like application portfolio management and Configuration Management Database (CMDB). By automating the discovery of application components and resources, you can gain a comprehensive view of your application landscape. Consolidating all relevant data into a single management console provides a holistic perspective. This approach should encompass both software components and infrastructure resources, encompassing different environments such as development, staging, and production. By clearly delineating these environments, you can better understand the context in which application issues occur. To facilitate quicker and more consistent resolution of operational issues, consider automating your runbooks. By automating routine operational tasks and predefined procedures, you can streamline the response to incidents and reduce manual effort. In summary, by leveraging a single management console, integrating with other operational systems, and automating runbooks, you can effectively manage your applications, investigate issues efficiently, and expedite the remediation process. ConclusionIn this final articles in our series on the AWS Cloud Adoption Framework (AWS CAF), we have explored the Operations Perspective and its critical role in driving the success of cloud adoption initiatives, examining the key capabilities and best practices that empower organizations to optimize the health, availability, and performance of their cloud services within the AWS ecosystem. By embracing the Operations Perspective, organizations can leverage automation, real-time insights, and robust incident response mechanisms to maintain the reliability, security, and performance of their cloud workloads. This holistic approach to operations fosters agility, reduces downtime, and enhances the overall efficiency of cloud environments. As we conclude this series on AWS CAF, it is essential to reflect on the wealth of knowledge we have gained throughout the various perspectives. We have explored the Business, People, Governance, Platform, Security, and Operations Perspectives, collectively providing a comprehensive framework for successful cloud adoption journeys. By adopting AWS CAF as a guiding principle, organizations can align their strategies, optimize resources, and achieve their desired business outcomes in the cloud. The series has equipped cloud architects, IT professionals, and decision-makers with practical insights and actionable steps to navigate the complexities of cloud adoption and unlock the full potential of AWS services. As technology continues to evolve, the AWS Cloud Adoption Framework remains a valuable resource for organizations embarking on their cloud transformation journeys. By leveraging the framework's principles and applying the knowledge gained from this series, businesses can confidently navigate the ever-changing landscape of cloud computing, ensuring long-term success and innovation. I hope that this series has provided you with the necessary guidance and inspiration to embrace the AWS Cloud Adoption Framework and embark on a transformative cloud journey.
0 Comments
Leave a Reply. |
AuthorTim Hardwick is a Strategy & Transformation Consultant specialising in Technology Strategy & Enterprise Architecture Archives
June 2023
Categories
All

|
